

Imagine you are running a digital platform where adults share creative work or connect with others. One day, your servers spike. Traffic looks normal at first glance, but then the reports start coming in: stolen identities, coordinated harassment campaigns, and automated bots flooding your community with spam. If you rely on manual review, you will drown in tickets before lunch. This is why modern platforms have shifted from reactive policing to proactive risk scoring models. These systems act as an invisible shield, evaluating every action a user takes in real-time to decide whether it’s safe, suspicious, or outright fraudulent.
The stakes are particularly high when dealing with adult user accounts. Unlike general social media, these spaces often involve financial transactions, sensitive personal data, and strict legal compliance requirements. A single breach can lead to severe reputational damage, regulatory fines, and loss of trust. Understanding how these scoring models work isn’t just for data scientists; it’s essential for anyone involved in platform governance who wants to protect their community without stifling legitimate engagement.
What Is a Risk Score?
At its core, a risk score is a numerical value assigned to a specific user action or account status. Think of it like a credit score, but for behavior on your platform. Instead of predicting loan repayment, it predicts the likelihood of abuse. When a user logs in, uploads content, or attempts a transaction, the system instantly calculates this score based on dozens-or even hundreds-of variables.
Risk Score is a quantitative metric used by platforms to assess the probability that a user account or action involves malicious intent, such as fraud, spam, or policy violations. It typically ranges from 0 to 100, where higher numbers indicate greater danger. For example, a new account logging in from a known proxy server might receive a score of 85, triggering immediate scrutiny, while a long-standing user accessing their profile from a familiar device might get a 5, allowing seamless access.
This dynamic evaluation happens in milliseconds. The beauty of this approach is flexibility. You don’t have to block everything that looks slightly odd. Instead, you can set thresholds. Scores below 30 might pass through automatically. Scores between 30 and 70 could trigger step-up authentication, like asking for a code sent to the user’s phone. Scores above 70 might result in temporary suspension pending human review. This tiered response saves resources and reduces friction for genuine users.
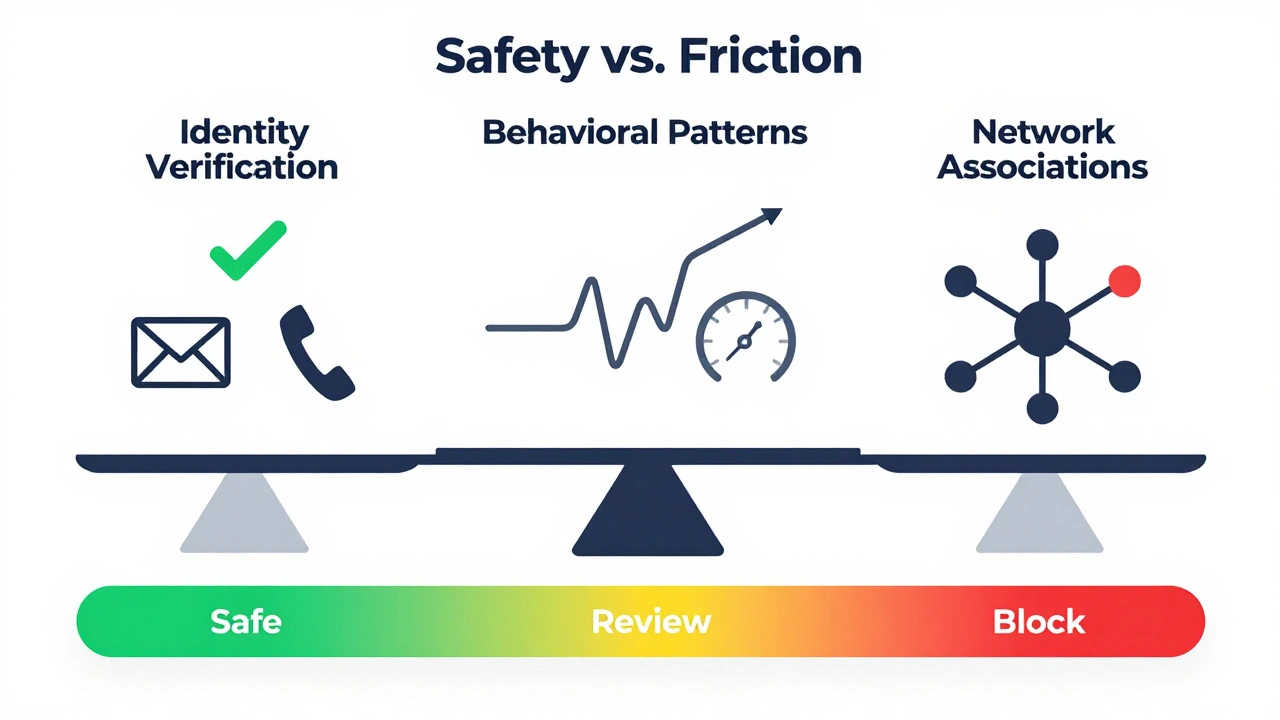
Key Signals That Drive the Algorithm
So, what goes into calculating this number? It’s not magic; it’s math applied to observable behaviors. Platforms analyze three main categories of signals: identity verification, behavioral patterns, and network associations.
- Identity Verification: Does the email domain look legitimate? Is the phone number associated with previous bans? Has the IP address been flagged in global threat intelligence databases? For adult platforms, verifying age and consent is also critical, so discrepancies here heavily weigh against the user.
- Behavioral Patterns: How fast is the user acting? A human typing a message takes time; a bot sends thousands of messages per second. Are they clicking links randomly? Do they view pages in a logical sequence? Machine learning models detect anomalies in mouse movements, scroll depth, and session duration.
- Network Associations: Who else is this user interacting with? If an account connects with ten other accounts that were recently banned for fraud, the model flags it as part of a potential ring. Graph analysis helps map these hidden relationships.
For instance, consider a scenario where a user suddenly changes their billing address to a country known for high chargeback rates and immediately tries to purchase premium credits. The model sees the geographic shift, the payment method change, and the timing. Each factor adds points to the risk score. Individually, none might be alarming. Together, they paint a clear picture of potential fraud.
Machine Learning vs. Rule-Based Systems
Early platforms relied on simple rule-based systems. "If IP matches blacklist, block." "If password is '123456', reject." While easy to implement, these rules are brittle. They miss novel attacks and generate false positives for innocent users who happen to trigger a rigid condition. Modern approaches use machine learning (ML) models, specifically supervised learning algorithms trained on historical data of confirmed fraud and legitimate activity.
| Feature | Rule-Based System | Machine Learning Model |
|---|---|---|
| Adaptability | Low; requires manual updates | High; learns from new data continuously |
| Detection Rate | Good for known threats | Excellent for emerging and complex patterns |
| Maintenance Cost | High over time due to rule sprawl | Moderate; requires data pipeline management |
| Explainability | High; clear if-then logic | Variable; depends on model type (e.g., decision trees vs. neural nets) |
ML models excel because they understand context. They know that a sudden login from abroad might be risky for one user but normal for another who travels frequently. However, ML isn't perfect. It requires clean, labeled data. If your training data is biased-for example, if it disproportionately flags certain demographics-the model will perpetuate those biases. Regular auditing is non-negotiable.
Handling False Positives and Negatives
No system is flawless. In risk scoring, there are two types of errors: false positives and false negatives. A false positive occurs when a legitimate user is incorrectly flagged as risky. This frustrates customers, leads to support tickets, and can cause churn. A false negative is worse in some ways: a fraudulent actor slips through undetected, causing financial loss or harm to the community.
Platform governors must find the right balance. This is often visualized using a Precision-Recall curve. Increasing sensitivity catches more fraud but also blocks more good users. Decreasing sensitivity lets more bad actors in but keeps the experience smooth for everyone else. For adult platforms, the cost of a false negative (e.g., allowing illegal content or financial theft) is usually higher than the inconvenience of a false positive. Therefore, many platforms err on the side of caution, implementing robust appeal processes to quickly reinstate wrongly blocked users.
To mitigate false positives, use multi-factor authentication (MFA) as a secondary check rather than an immediate ban. Ask the user to verify their identity via SMS or authenticator app. Most fraudsters won’t bother completing this step, while legitimate users will appreciate the extra security layer.
Real-Time Processing Challenges
Speed matters. If your risk scoring engine takes five seconds to evaluate a login attempt, users will abandon the process. Real-time processing requires low-latency infrastructure. Technologies like Apache Kafka for streaming data and Redis for caching allow platforms to score actions in under 100 milliseconds.
However, complexity increases with scale. As your user base grows, so does the volume of data. You need efficient feature engineering pipelines that extract relevant signals without bogging down the system. For example, instead of storing every single click, aggregate them into metrics like "average clicks per minute" or "unique pages visited per session." This reduces storage costs and speeds up computation.
Another challenge is concept drift. Fraud tactics evolve. What worked last year might be obsolete today. Your models need continuous retraining with fresh data. Automated MLOps pipelines can help monitor model performance and trigger retraining when accuracy drops below a certain threshold.

Ethical Considerations and Transparency
Using algorithms to judge people raises ethical questions. Users deserve to know why they were blocked or restricted. Black-box models, especially deep neural networks, can be difficult to interpret. Regulatory frameworks like GDPR in Europe emphasize the right to explanation. If a user appeals a decision, you should be able to provide a reason, even if simplified.
Techniques like SHAP (SHapley Additive exPlanations) values can help break down which features contributed most to a high risk score. For example, you might tell a user, "Your account was flagged because the login location differs significantly from your usual pattern and the device fingerprint is unrecognized." This transparency builds trust and helps users correct issues, like updating their travel settings.
Additionally, ensure fairness across demographic groups. Audit your models regularly for bias. If certain regions or languages are disproportionately flagged, investigate why. Is it a data quality issue? A cultural misunderstanding in the algorithm? Addressing these gaps is crucial for maintaining an inclusive and safe environment.
Building a Robust Governance Framework
Risk scoring is just one piece of the puzzle. Effective platform governance combines technology with policy and human oversight. Start by defining clear policies on what constitutes abuse. Then, align your scoring thresholds with these policies. Train your human review team to handle edge cases that the model can’t resolve. Create feedback loops where reviewers’ decisions improve the model over time.
Regularly test your system with red team exercises. Simulate various attack scenarios to see how well your models detect them. Update your rules and retrain your models based on findings. Stay informed about industry trends and emerging threats. Collaboration with other platforms through information-sharing initiatives can also enhance collective defense against sophisticated fraud rings.
Remember, the goal isn’t perfection-it’s resilience. By implementing thoughtful risk scoring models, you create a safer space for your users while minimizing disruption to their experience. It’s a balancing act, but with the right tools and mindset, it’s entirely achievable.
How accurate are risk scoring models for detecting fraud?
Accuracy varies depending on data quality and model sophistication. Well-tuned machine learning models can achieve detection rates above 90% for common fraud types. However, no system is 100% accurate. Continuous monitoring and adjustment are necessary to maintain high performance as fraud tactics evolve.
Can users appeal a high risk score?
Yes, reputable platforms provide an appeal mechanism. When a user is flagged, they should be able to contact support to review their case. Human reviewers examine the evidence and can override the automated decision if it was incorrect. Providing clear reasons for the flag helps users understand and rectify the situation.
What data is needed to build a risk scoring model?
You need historical data on both legitimate and fraudulent activities. Key data points include login timestamps, IP addresses, device fingerprints, transaction amounts, user interaction patterns, and outcomes of past investigations. The more diverse and labeled your dataset, the better your model will perform.
Is it expensive to implement risk scoring?
Initial setup costs can be significant due to data infrastructure and expertise required. However, the long-term savings from reduced fraud losses and lower manual review costs often outweigh the investment. Many cloud providers offer managed ML services that reduce upfront development effort.
How do I prevent my model from becoming biased?
Regularly audit your model for disparate impact across different user groups. Use fairness metrics during training and testing. Ensure your training data represents all segments of your user base equally. Implement explainability tools to identify and correct biased decision paths.